The Problem
Vendr is a SaaS procurement platform. Its marketplace lets software buyers request Price Estimates and Price Checks on software products, giving them benchmark pricing data they can use to negotiate better deals. The buyers are executives, department heads, and procurement specialists at companies of all sizes, from startups to large enterprises.
In October 2024, Vendr launched a redesigned marketplace experience. The redesign was a strategic bet: shift from a concierge-heavy sales model to a self-service marketplace where visitors could request pricing intelligence directly, without talking to a human. The theory was that frictionless access to pricing data would attract a broader audience, generate leads, and convert a percentage of those visitors into paying customers.
The problem was that nobody knew whether the redesigned marketplace was working. Traffic was coming in. People were requesting Price Estimates. But the company had no systematic understanding of who these visitors were, what they expected, what they thought of the experience, or whether they intended to come back.
This was a classic product-market fit question, and it needed to be answered with real data from real users. It was also, at its core, a human-automation trust problem: visitors were being asked to trust algorithmically generated price intelligence in place of a human negotiator, and we didn't know whether they would.

How We Worked
The project ran from late October 2024 through February 2025. I used a mixed-methods approach combining semi-structured interviews with a quantitative product-market fit measure. We reached out to approximately 115 people who had recently requested a Price Estimate or Price Check, and conducted 26 sessions. The majority of participants were executives or department heads: CMOs, cofounders, VPs, directors, and team leads from companies ranging from early-stage startups to subsidiaries of large enterprises. Most came to Vendr to research pricing for an upcoming SaaS purchase. Two were conducting competitive intelligence. One was seeking a SaaS product to recommend to a client.
They requested Price Estimates for products across the SaaS landscape: HubSpot, Vanta, Carta, Salesforce, Adobe, DataDog, ZoomInfo, DocuSign, Asana, and many others. This diversity was useful because it meant we saw the experience across a range of data quality conditions, from products where Vendr had strong pricing data to products where the data was thin.
Recruiting was scrappy and continuous. Each week I pulled new requestor data from Mixpanel, cross-referenced against Sales activity to avoid collision, and reached out via LinkedIn. We offered $100 for a 30-minute conversation.
The interview protocol was structured around four areas: the participant's job role and procurement maturity, how they discovered Vendr and what they expected, their reactions to the request process and the deliverable, and a set of standardized quantitative questions including the Superhuman PMF disappointment question ("How disappointed would you be if you could no longer use Vendr?").
During each session, I coded participants on procurement maturity, decision-making authority, purchase stage, and supplier engagement level. This gave us a structured dataset alongside the qualitative narratives.
The analysis workflow for this project required solving a specific problem: 26 sessions generated hundreds of pages of transcripts and session summaries, and the product and marketing teams needed answers faster than a traditional qualitative analysis cycle could deliver. NotebookLM had launched only a few months earlier, and I saw an opportunity to restructure the analysis around it. I loaded the full corpus into NotebookLM, which cut analysis time by at least 50%. But the more significant outcome was what it enabled downstream: I shared the NotebookLM project directly with Product and Marketing, giving them a queryable research archive they could interrogate on their own schedule without waiting for a formal readout. This is what supervised automation looks like in research practice: the tool handles retrieval and pattern-surfacing at scale, the researcher maintains control over interpretation and recommendations.
What We Found
The findings broke cleanly into two categories: the encouraging signals and the structural problems.
The Encouraging Signals
Visitors value Price Estimates. When the data was good, participants derived significant value. Narrow, SKU-specific price ranges gave them confidence in their purchasing decisions and leverage in negotiations. One growth consultant described using a Vendr estimate as "a sanity check" that gave him the confidence to push back on a supplier's pricing. A cofounder found the $10K to $30K range for Vanta helpful, noting that a sample size of 200 deals felt solid. A procurement specialist was surprised by how fast the analysis came back, compared to weeks of waiting he was used to with suppliers directly.
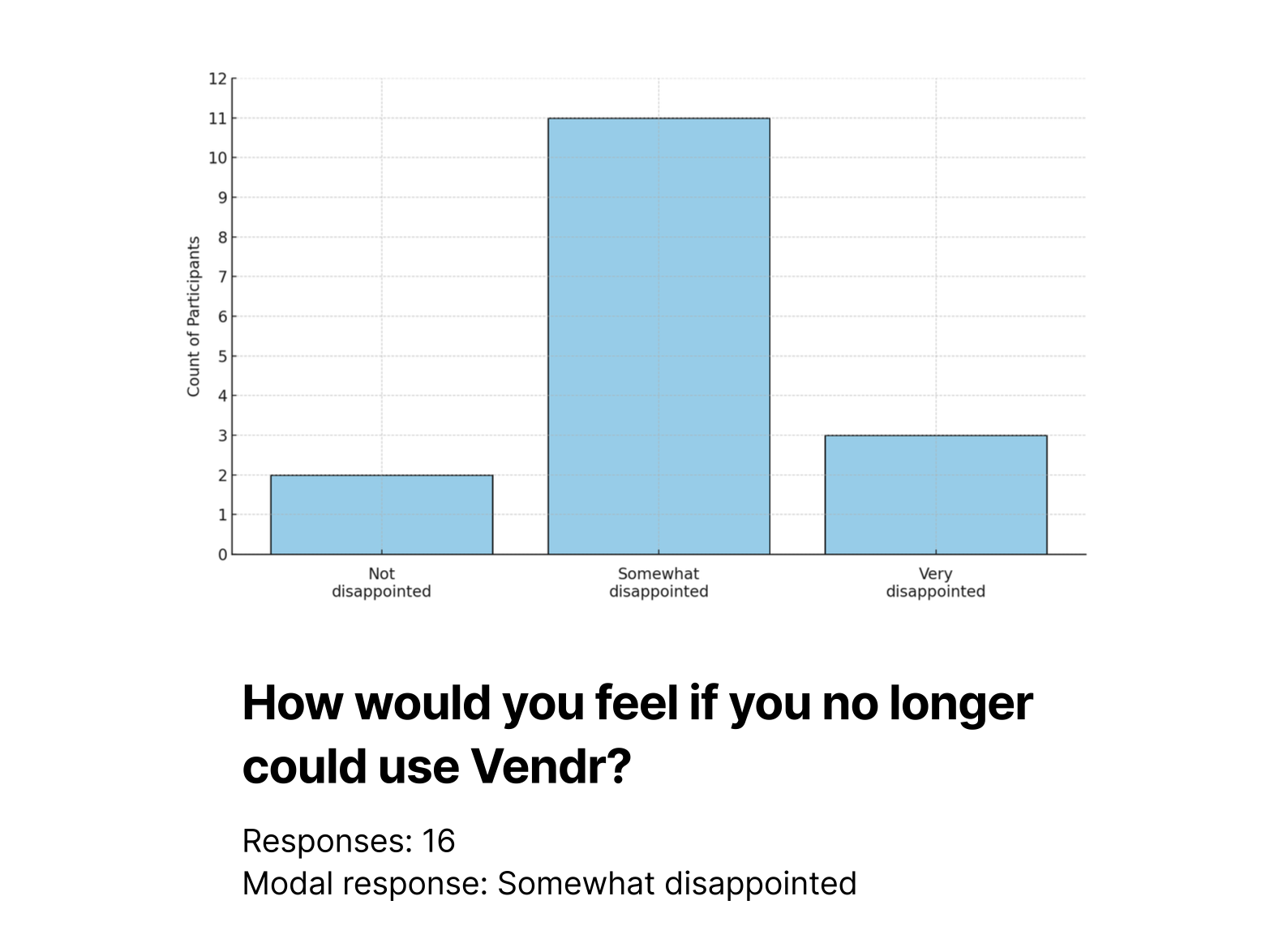
They intend to return. We measured return intent with the Superhuman PMF disappointment question. Of the 16 participants who responded, 11 said "Somewhat Disappointed," 3 said "Very Disappointed," and only 2 said "Not Disappointed." That 69% "Somewhat" or "Very" disappointed rate indicated real perceived value, even if the product wasn't yet at the 40% "Very Disappointed" benchmark that Sean Ellis uses as the PMF threshold.
They're rooting for Vendr. This was the qualitative finding that surprised me most. Every participant recognized that Vendr was trying to fix the broken software procurement process, even when they couldn't articulate exactly what Vendr offers. When their Price Estimate ranges were unreliable, they were still willing to come back in the future to see if the data improved. That's brand equity, and it was substantial.
The Structural Problems
Visitors don't understand what Vendr does. Participants arrived with a range of expectations, most of them wrong. Some expected Vendr to facilitate direct quotes from suppliers. Others anticipated that a supplier representative would reach out after submitting a request. One CMO had a vague "hunch" about negotiation support but lacked any real understanding of it. Another participant wasn't sure whether Vendr was a marketplace, a benchmarking tool, or a negotiation platform.
This was a positioning and messaging problem, not a product problem. The marketplace itself functioned fine. But visitors were forming their own mental models of what Vendr does, and those models were wildly inconsistent with each other and with reality.
They want more transparency. This manifested in two ways. First, participants wanted to know how Vendr makes money. Several expressed concern that Vendr, as a middleman, would necessarily add cost to their purchase. One Head of Brand said he saw "at no cost" on the site but was "a little bit leery about that." Second, participants were reluctant to upload quotes or contracts because Vendr didn't explain its data retention and privacy practices. Multiple participants said they would only upload a document if the site explicitly stated the quote would be deleted after the price range was computed. One participant suggested allowing users to type in values from a form rather than uploading confidential documents.
This was the same trust calibration problem I've studied since my dissertation work in aviation automation: when users can't see how a system works or what it does with their data, they default to distrust. The Price Check feature required a document upload, and users were declining to use it because they didn't trust the black box. Trust was directly depressing conversion.
Low data quality reduced the value of Price Estimates. When price ranges were wide, participants found them useless. One cofounder described a range of "$12K to $60K" as "the difference between an old used car and a swanky Tesla." Another got a range of $5,000 to $200,000 and pointed out it wasn't tied to their business at all. A third found the Vanta estimate helpful at $10K to $30K, but the Carta estimate at "$20K to six figures" was impossible to act on.
Participants also wanted more granularity. They didn't just want a total cost range. They wanted to understand how different features and units contributed to the overall cost. One growth consultant noted that CRMs build quotes by stacking features and units, and if Vendr could account for that, it would solve a significant usability gap.
Visitors aren't sure what to do next. After receiving their estimate, participants hit a dead end. The distinction between "Customize my Price" and "Upload my Quote" confused several of them. One director of marketing automation scrolled back and forth on the page, unable to find a clear path to a Price Check. Others expected email notifications when their estimate was ready and never received them. The marketplace experience was fragmented: each interaction felt like a dead end rather than a step in a longer journey.
What I Recommended
The recommendations mapped directly to the four structural problems.
Set accurate and aspirational expectations. I delivered a messaging framework to Marketing tied to specific moments in the buyer's journey: when building a shortlist, Vendr saves time with pricing data unavailable elsewhere. When evaluating a quote, Vendr saves money by benchmarking the deal. When ready to buy, Vendr negotiates on the buyer's behalf. When renewing, Vendr helps attain the best renewal price. The framework gave Marketing and Product firm positioning statements to set expectations up front.
Build trust. I provided specific design recommendations: explain the value users get for uploading a quote, provide a clear and accessible data privacy policy, explicitly state whether quotes are deleted after processing, offer a manual data entry option as an alternative to document upload, and be transparent about how Vendr generates revenue.
Provide better journey signposting. I also generated a set of UX recommendations: clarify next steps based on user intent, offer relevant calls to action at each stage, and create a more unified experience so visitors could quickly recognize what Vendr offers, why each capability is valuable, and how to use it given their current place in the purchase journey.
Enhance the Price Estimate deliverable. I delivered data quality and content recommendations: improve data quality with more granular, SKU-specific data; explain how estimates are calculated; include implementation costs; allow users to tweak parameters after the fact; and add intelligence content like product overviews, feature descriptions, and peer reviews.
Double down on nurture campaigns. I provided an actionable retention strategy and streamlined "to-be" journey: email Price Estimates directly to users, clearly communicate next steps, and continue follow-up campaigns to establish the Vendr habit.
What I Learned
This project reinforced several things I've come to believe about doing research at startups, and it taught me one new thing.
Continuous recruiting beats batched recruiting for marketplace research. We pulled new requestor data weekly, which meant we were always talking to people whose experience was fresh. By the end of the study, we had a longitudinal view of how the experience was evolving as the product team shipped changes in parallel.
The PMF disappointment question is useful, but the qualitative data around it is more useful. The 69% "Somewhat or Very Disappointed" number was a helpful signal, but it was the surrounding conversation that made it actionable. When someone says "Somewhat Disappointed" and then adds "I would definitely use it again, the information was helpful, maybe not super specific, but helpful enough" -- that tells you exactly what to fix.
AI-enhanced analysis is a force multiplier, not a replacement. NotebookLM cut my analysis time in half, but more importantly, it democratized access to the data. Product managers and marketers could ask their own questions of the transcripts without waiting for a research readout. That changed the dynamic from "research delivers findings" to "research enables organizational learning." This is what supervised automation looks like in practice: the tool handles retrieval and pattern-surfacing, the researcher maintains judgment over what it means and what to do about it.
The deeper lesson from this project is about product-market fit research at the marketplace stage. Marketplaces have a chicken-and-egg problem: you need supply-side quality (good data) to attract demand-side usage (visitors who return), but you need demand-side usage to justify investment in supply-side quality. The research showed that Vendr had strong demand-side signals: visitors valued the product, intended to return, and were rooting for the company to succeed. But the supply-side quality gap - wide price ranges, missing SKUs, lack of granularity - was eroding the very trust that the brand equity was building. The recommendation wasn't just "improve data quality." It was "protect and capitalize on the brand equity you've earned while you close the data quality gap, because that equity is a perishable asset."